 I'm Max Desiatov, a Ukrainian software engineer.
I'm Max Desiatov, a Ukrainian software engineer.Event loops, building smooth UIs, and handling high server load
16 August, 2018This article is a part of my series about concurrency and asynchronous programming in Swift. The articles are independent, but after reading this one you might want to check out the rest of the series:
- How do closures and callbacks work? It’s turtles all the way down
- Event loops, building smooth UIs, and handling high server load
- Introduction to structured concurrency in Swift: continuations, tasks, and cancellation
Have you ever used an app that felt unresponsive? Not reacting to input on time, slow animations even for some simple tasks, even when there isn’t anything heavy running in the background? Most probably, an app like that is waiting for some blocking long-running computation to finish before consuming more user input or rendering animation frames. Scheduling all workloads correctly and in the right order might seem hard, especially as there are different approaches to choose from.
What does it mean to be “non-blocking”?
When developing native apps for iOS, we always have this thesis: “avoid blocking the main thread”. Due to the fact that UIKit and AppKit APIs are not thread-safe, most if not all UI rendering happens on the main thread. If you have a long-running blocking computation on that thread, your app isn’t able to respond to user input or to render UI updates.
For an app to feel smooth and interactive on a device with 60 Hz display refresh rate, it has to render 60 frames a second and update those in response to user input as close possible to real time. That means you as a developer only have about 16.6 milliseconds of run time in event handlers on the main thread to complete. Want the app to feel smooth on 120 Hz iPad Pro? That’s 8.3 milliseconds on the main thread at your disposal.
Here’s a conceptual diagram of CPU load on the main thread that refreshes UI at 60 Hz and runs a blocking operation on the main thread. Red solid spikes in CPU load are caused by UI rendering code, while blue ones are caused by HTTP client code.
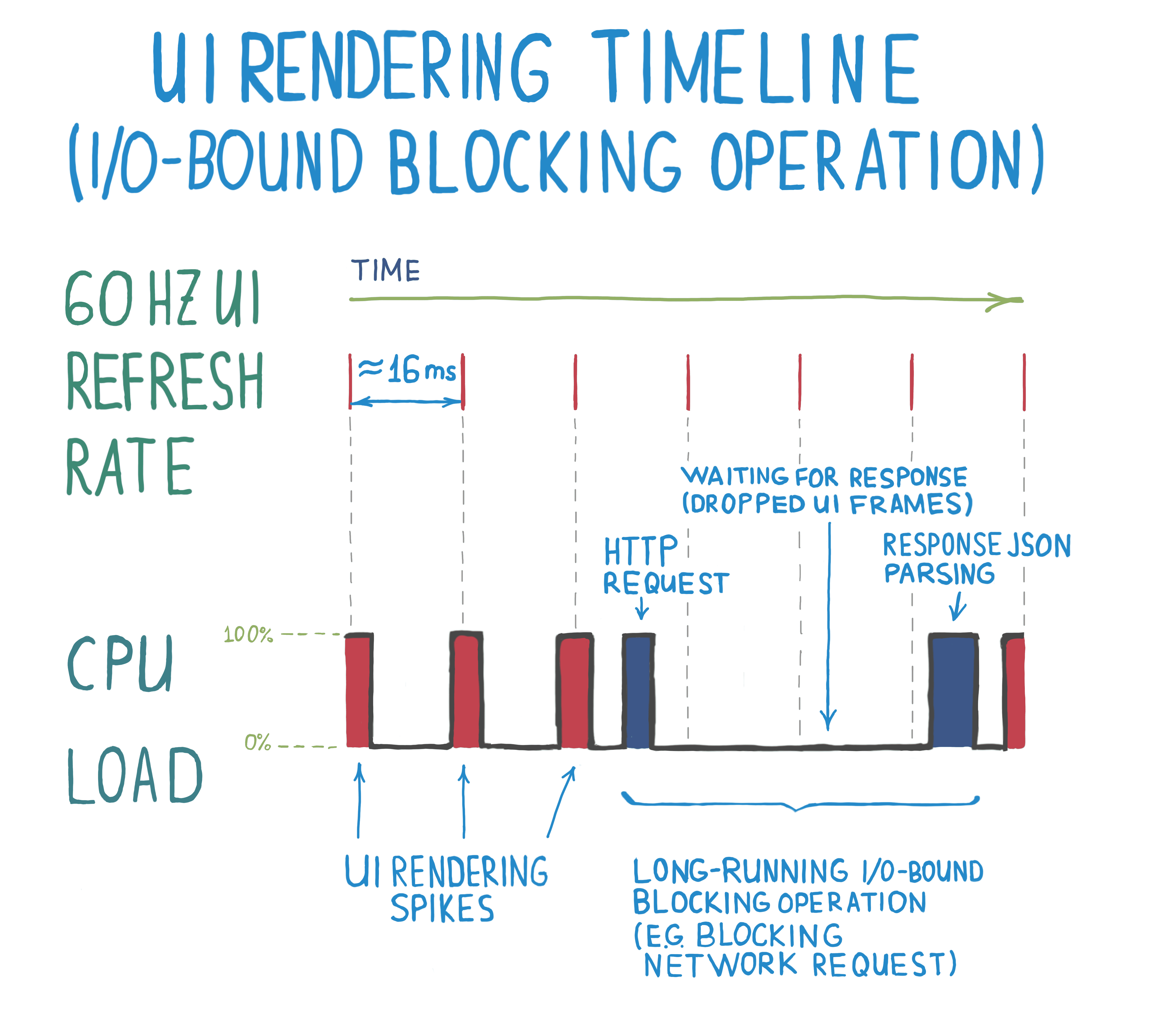
As you can see, if an HTTP client operation is blocking and runs for more than 33 milliseconds, up to 3 UI frames would not be rendered. Imagine if the request runs on a slow network and takes seconds to complete, the app UI would freeze and be unresponsive during all that time.
The important thing to note on the diagram is that CPU stays idle while waiting for the network operation to complete, so in principle, it could have rendered the frames while waiting. This type of operation is called I/O-bound, which means that a bottleneck in the operation is I/O (filesystem access, networking, communicating with sensors and peripherals etc) rather than intensive computations on the CPU. On the contrary, operations where CPU load is a bottleneck are called CPU-bound operations. This distinction is quite important, it turns out it’s quite easy to make I/O-bound code non-blocking.
Event loops
How do people avoid blocking the main thread with I/O-bound code? Here’s one approach: as soon as main app initialisation has finished, an event loop is started (also known as a “run loop” in Cocoa/Foundation/GCD world). It is a loop that processes I/O events and invokes corresponding event handlers at each iteration. While the loop is not truly infinite, certain exit events, say a user closing the app, would clean up the resources and stop the loop. But it’s indefinite in a sense that usually there’s no predefined number of iterations when it starts.
Building smooth UIs
Most of the code an iOS/macOS developer writes is called from an event loop iteration. All gesture recognisers, sensors input and higher level event handlers such as button taps and navigation handlers are invoked on the main thread and are scheduled by an event loop. This is applicable to browser apps too: all your code (except web workers) runs on the same thread and blocking computations would make UI freeze. In the end, the browser is just a native application with its own event loop that forwards native events to your JavaScript code.
Here’s an example of a stacktrace of a native iOS app, which shows event loop functions at the bottom of the stack:
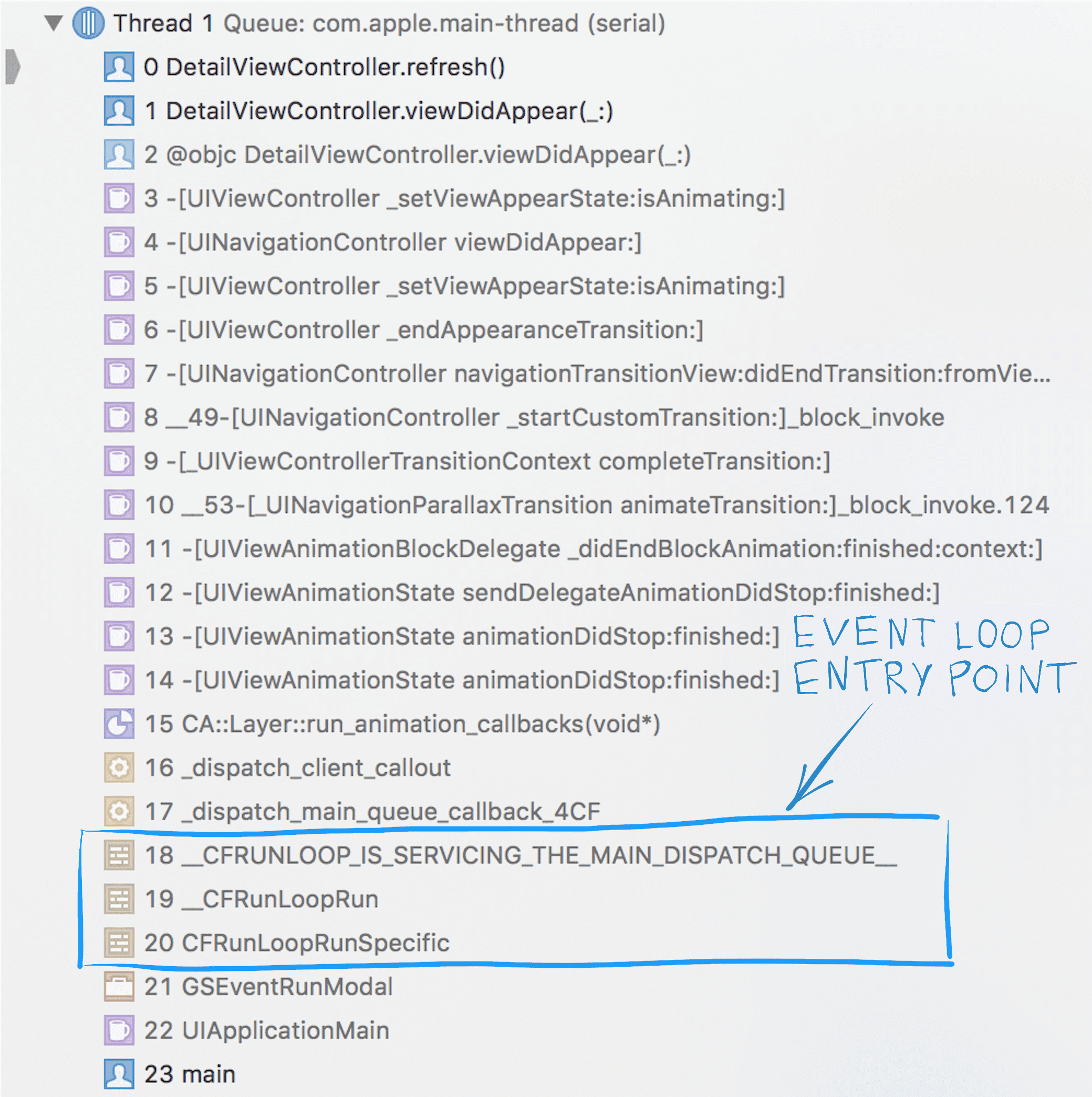
I bet, in 90+% of the cases when debugging the main thread of iOS apps, you’d see these calls at the bottom of a stacktrace. It’s an implementation detail that’s hidden quite well from us, but a very important one.
How would an event loop fix our UI example with a blocking HTTP client? We saw from the CPU load on the diagram that this operation is composed of two parts: forming a request and parsing a response. Quite simply, we could run request formation as soon the operation starts and then schedule response parsing on a subsequent event loop iteration to be called only when this response is ready.
Here’s a diagram of the same UI example with an event loop:
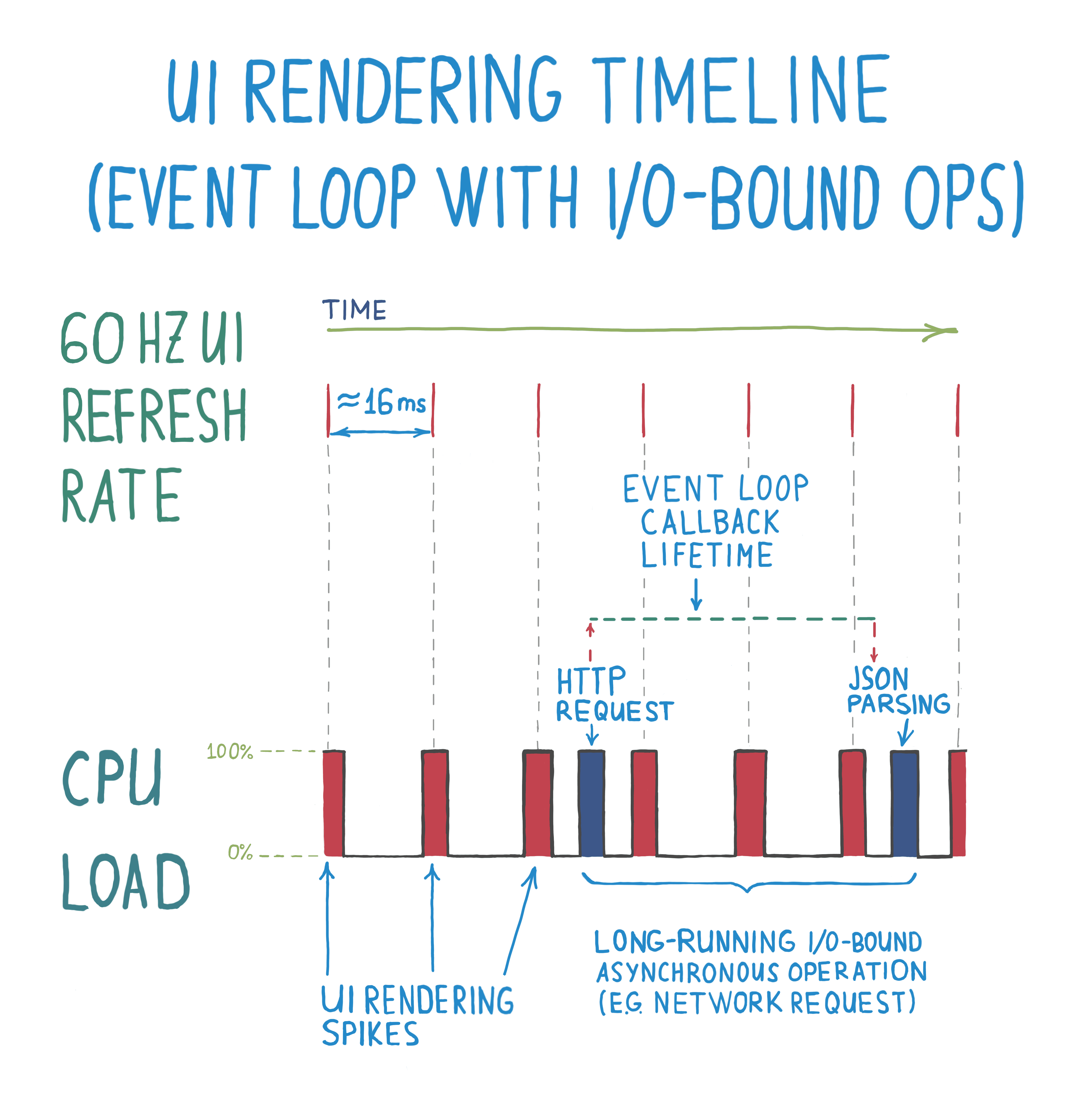
A notable change here is the introduction of callbacks. Instead of performing an I/O-bound operation all at once, it is split into multiple parts, which are chained with a callback. For example, in Swift a callback could be created in a form of a closure:
let session = URLSession.shared
session.dataTask(with: URL(string: "https://your.api/call")!) {
data, response, error in
// ...
}or a delegate object:
class Delegate: URLSessionTaskDelegate {
func urlSession(_ session: URLSession,
task: URLSessionTask, didCompleteWithError: Error?) {
// ...
}
}
let task = session.dataTask(with: URL(string: "https://your.api/call")!)
task.delegate = Delegate()or even with target-action pattern (usually reserved for UI handlers):
class Controller: UIViewController {
func viewDidLoad() {
super.viewDidLoad()
let button = UIButton(type: .custom)
button.addTarget(self, action: #selector(handler),
for: .touchUpInside)
view.addSubview(button)
}
@objc func handler() {
// ...
}
}All of these patterns are enabled by event loops. On a higher level, the existing event loop is able to invoke these callbacks at some later iteration without blocking other code.
Handling high HTTP server load
Even if you aren’t working on the full stack, as a frontend dev you might be interested how those servers can handle the increased amount of requests from your smooth apps powered by event loops. And if you’re a backend dev, I hope that previous section was not too boring and you like this one even more. 😄
Now imagine an HTTP server processing a high amount of requests coming at the same time. Firstly, a request is parsed to get a few parameters and then the server issues a query to a database with the parameters. After the query is finished, a response is formed with the query result and sent to a client.
It’s easy to see with an abstract CPU load diagram how a blocking database query can kill the server’s throughput. On the following diagram there are three separate CPU load spikes for every request and response sequence:

While HTTP servers don’t drop UI animation frames like in the UI example, a blocking operation makes a client wait in a queue for a response until requests are processed one by one. Of 6 requests shown, only 4 were handled by the end of the diagram timeline. Again, it’s obvious that a database query is I/O-bound and you could have processed many requests simultaneously. This would also saturate CPUs more efficiently, which is quite important in reducing the cost of running servers.
You probably have guessed by this point, event loops come to the rescue! 😄 What if the server started parsing a response as soon as it’s received, not waiting for a database query of a previous request to complete? As I’ve marked three steps of the operation in different colours, you can see that parts of asynchronous request handling are executed out of order on a linear CPU timeline. It doesn’t mean anything’s wrong, as HTTP is a stateless protocol, you can assume that requests are independent and can be processed simultaneously.
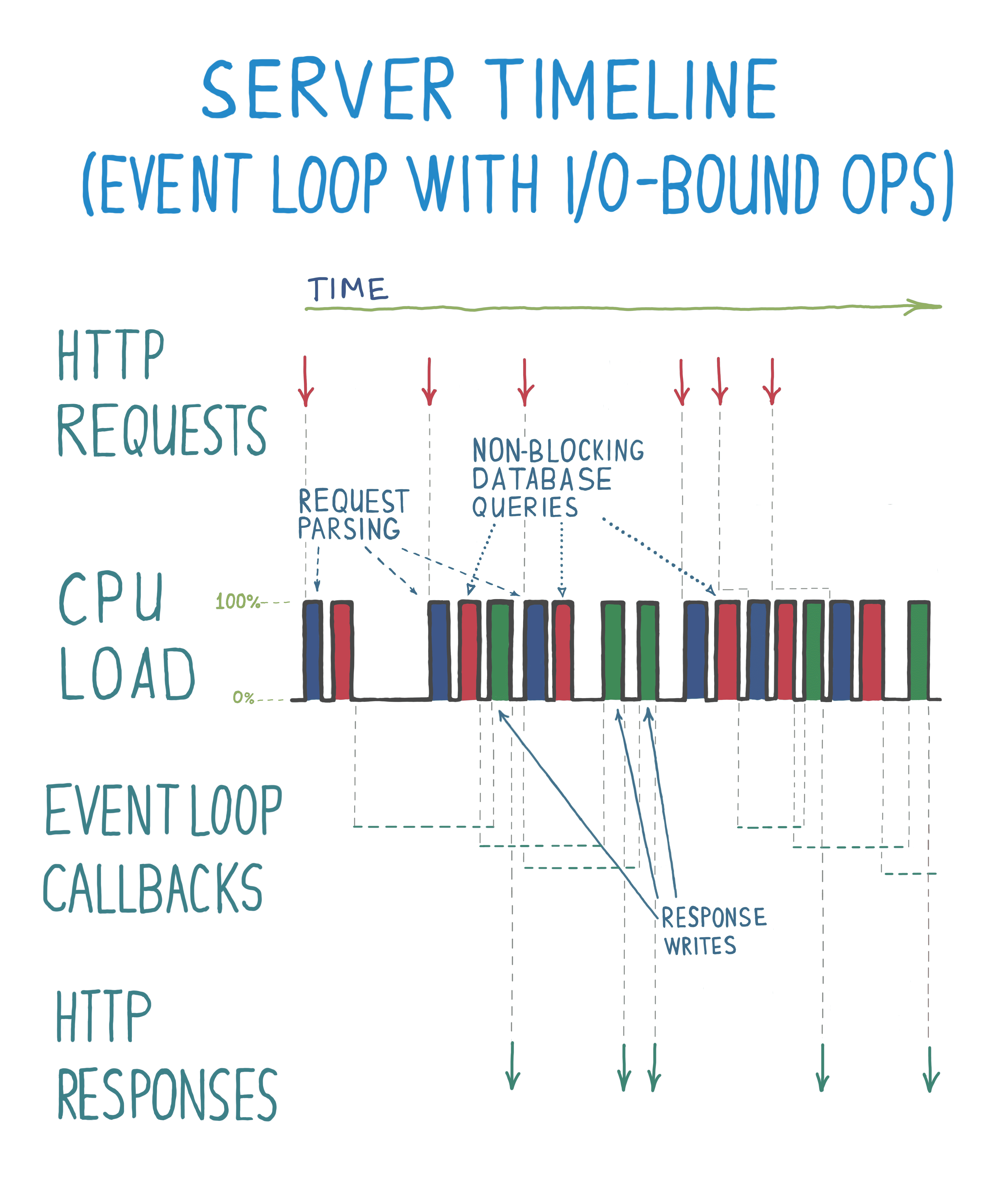
Overall, we can’t say that database queries became faster when you look at a given request and response pair. But throughput is much better thanks to the introduction of an event loop (assuming your database is able to handle the increase). For 6 requests by the end of diagram’s timeline, 5 responses were issued, and it was done much earlier than it would have happened in a blocking version. The CPU load is more evenly distributed within one process, which reduces context switching overhead and server cost.
Current status of event loops on the server side
Nowadays, if you write server-side code, quite probably you already use an event loop under the hood. Let’s have a quick overview of how major languages and frameworks actually do this.
Node.js provides an implicit event loop in a
single thread that you work with. setTimeout, setImmediate and setInterval
functions schedule closures to be executed
later by the default event loop. Turns out, ASP.NET Core supports non-blocking
I/O
out of the box. This may not be so surprising, given that C# supported async
methods since
2012. If
you’re into JVM ecosystem,
Netty is the way to go with event loops. And you probably
heard of it, Norman Maurer, one of the main
contributors to Netty now works for Apple and is a top committer to the new
SwiftNIO framework.
Now we’ve mentioned Swift, Vapor 3.0 already migrated to SwiftNIO and there’s also a “tech preview of Kitura on SwiftNIO” available. Interesting to note that SwiftNIO allows you to utilise event loops across multiple threads.
Scaling event loops across multiple threads is a very powerful concept and is something that’s also already available on the language level in Go and Elixir. While I have my share of scepticism for both Go1 and Elixir2, these are very interesting languages that I highly recommend to explore and wrap your head around.
In our day and age of diminishing returns from Moore’s law, being able to easily scale tasks across multiple CPU cores, GPUs and other devices is indispensable. Concurrency, parallelism and distributed computing is the new functional programming. 🤓 In some sense, these topics initially seem to be difficult and obscure, but can drastically improve how you approach different problems when you have at least some understanding of basic concepts.
How do you even deploy a backend app without an event loop?
For quite some time event loops weren’t as popular in backend software as they are now. Back in the 90s, spawning a new process for every HTTP request seemed normal, I refer you to the history of Common Gateway Interface for more info on this. A few optimisations followed, like SCGI and FastCGI, but they still maintained a clear separation between an HTTP server and request handling itself. An HTTP server (e.g. Apache) could have used an event loop on the lower level, but the application logic still lived in a separate process. It was possible to eke out a bit more performance by spawning multiple worker processes or threads, but this still caused context switching overhead and same blocking I/O bottlenecks as previously.
You could’ve asked: “who even writes blocking HTTP code these days?“. Well, if
you’re writing code for Python 3.2 and older, most probably you don’t have
access to asyncio, which is Python’s
standard implementation of event loops. Most popular Python’s web frameworks
like Flask and Django
are synchronous, not powered by an event loop and are commonly deployed via
WSGI. The most
popular HTTP client library
requests provides only blocking
API as well.3 When you do have access to newer Python versions and to
asyncio, event loops there are
a bit more explicit than in Node.js, but the underlying concept is still the
same.
While I don’t have much exposure to Ruby and Ruby on Rails, in my research I haven’t found any event loop frameworks that have become mainstream. It does look like most common solutions for deployment utilise multithreading and multiprocessing to improve scalability.
Similarly with PHP, while ReactPHP is about 5 years old at this point, you can’t beat inertia of deploying WordPress on Apache. 😄
How do event loops work?
There is a ton of details hidden under the hood that we don’t need to worry about on a daily basis. After all, event loops are meant to improve how we work with I/O-bound tasks and most of I/O stuff can get complicated real quick.
A good explanation is this pseudocode from SwiftNIO documentation. As SwiftNIO is primarily a server-side framework, a channel here means a server connection established by a client. But on a low level, this is applicable to UI event loops too. From a certain perspective, interactions with touch sensors, display drivers and GPUs can be considered I/O.
while eventLoop.isOpen {
/// Block until there is something to process for 1...n Channels
let readyChannels = blockUntilIoOrTasksAreReady()
/// Loop through all the Channels
for channel in readyChannels {
/// Process IO and / or tasks for the Channel.
/// This may include things like:
/// - accept new connection
/// - connect to a remote host
/// - read from socket
/// - write to socket
/// - tasks that were submitted via EventLoop methods
/// and others.
processIoAndTasks(channel)
}
}Here blockUntilIoOrTasksAreReady interacts with sockets or
device drivers via system calls and provides events that are ready to process.
In turn, processIoAndTasks dispatches those events to corresponding callbacks
that were registered on previous event loop iterations.
Disadvantages of event loops
As I previously mentioned, the server-side event loop diagram is a bit harder to read when establishing the sequence of events. This especially might get in the way during debugging. In a function call stacktrace you probably would be able to see what kind of event led to a specific callback handler, but tracing it to the original code that scheduled the handler has to be done separately.
You might’ve stumbled upon a similar problem when debugging multithreaded code. A stacktrace of a particular thread can be retrieved, but by the time your point of interest executes, the original thread that scheduled the work has already moved on to completely different code.
In a situation with multiple threads, this can be further complicated by the use of synchronisation primitives and non-deterministic nature of thread scheduling. On the contrary, if your event loop code is single-threaded and tasks are scheduled and handled from the same thread, it’s not as bad.
A quite acceptable solution is to maintain a separate callback stack trace that can be examined later when needed. For example, SwiftNIO records file names and line numbers of futures and promises that were created. This information is then logged if a deallocated future was unfulfilled, indicating that there is a potential leak creating redundant future objects. In principle, a higher level framework (say an HTTP server) could attach richer information to its own stack of requests to be logged when something goes wrong.
Summary
It would be fair to say that an event loop is a great tool for building high-performance and scalable applications. We’ve looked into how it helps with both UI and server-side code. Specifically, on the server side, there are plenty of approaches, different languages and frameworks evolved in different ways that are still fundamentally the same under the hood.
Non-blocking I/O on a low level can be relatively tricky, and it’s great that event loops can abstract this away. There are a few caveats with regards to debugging event loop based code, but it’s something that can be overcome with tooling, better support from frameworks and runtime of a programming language that you use.
As with any tool, it’s important to know the use cases and apply it where it fits best. With event loops, you can get substantial gains in throughput and responsiveness of your apps if applied well, while paying a small cost of recording more runtime information to ease debugging if needed.
I hope I provided some information on that in the article, but please feel free to shoot a message on Twitter or Mastodon with your comments and questions. Talk soon. 👋
-
No generics in a statically typed language in 2018? Boilerplate error handling? Some say this all happened on purpose to keep things simple and minimalistic. Sorry, this doesn’t feel to me like minimalism, more like brutalism. 😄
↩ -
While Elixir is a great improvement on top of Erlang, limitations of dynamic virtual machines become too obvious when trying to write CPU-bound code. Calling into native binaries is quite difficult, but I love how Elixir makes distributed computing native to the language and its standard library.
↩ -
The situation with Python and blocking APIs is peculiar enough to be considered in more detail. I’m convinced that this is a great illustration of how important ergonomics of programming languages is. It was possible for a long time to build asynchronous non-blocking applications in JavaScript, especially with Node.js. New language features such as generators and
async/awaithave given JavaScript mostly syntax sugar to help with patterns that have been available for a while. Compare this with Python, where even in 2018 with the availability ofasync/awaitand new libraries based on event loops, a lot of people still hesitate to make a transition to non-blocking I/O.Admittedly, Python 2 to Python 3 migration could explain some of this conservatism, but it doesn’t explain the scarcity of callback-based APIs in Python 2. What is important to consider is a lack of a crucial, but frequently overlooked language feature: anonymous closures/lambdas with multiple statements. Lambdas in Python allow only a single expression within, and this prevents you from creating an ergonomic callback-based non-blocking API. While libraries such as Twisted existed at the time, their API based on delegates wasn’t very accessible.
In turn, delegates are pretty good when you’re able to express a required delegate shape with protocols/interfaces. Python lacks those too, although something similar can be hacked with abstract base classes.
↩
If you enjoyed this article, please consider becoming a sponsor. My goal is to produce content like this and to work on open-source projects full time, every single contribution brings me closer to it! This also benefits you as a reader and as a user of my open-source projects, ensuring that my blog and projects are constantly maintained and improved.