 I'm Max Desiatov, a Ukrainian software engineer.
I'm Max Desiatov, a Ukrainian software engineer.Introduction to structured concurrency in Swift: continuations, tasks, and cancellation
14 January, 2021
Around the time async/await proposal was accepted, I saw people asking almost the same set of questions: how to convert legacy APIs to async? How an entry point to async code would look like? While examples of usage of async/await in UIKit apps were shared around, there were no good examples that utilized the structured concurrency proposal. I wanted to have a look at some minimal isolated code snippets that could help me answer these questions.
Read more...
The state of Swift for WebAssembly in 2020 (and earlier)
16 September, 2020
The availability of a virtual machine in all relatively recent major browsers makes a lot of code much more portable. It easily follows that Swift targeting WebAssembly would essentially make Swift available in some form on all platforms that have browsers with WebAssembly support.
Read more...
How WebAssembly changes software distribution
09 September, 2020
WebAssembly is arguably a more direct path towards achieving the idealistic goal of “write once, run anywhere” than Java/JVM ever was. This is thanks to the open nature of the whole stack, potential developers mindshare (spanning big and diverse set of languages and ecosystems), and direct involvement of browser vendors such as Apple, Google, Mozilla and Microsoft.
Read more...
Unbreakable reference cycles in Swift no one is talking about
17 December, 2018
Value types and reference types in Swift involve different approaches to memory management: value types are implicitly copied while reference types only change their reference count when passed around. Without proper care, it's easy to create reference cycles which cause memory leaks. You might be tempted to avoid classes and stick to value types altogether to avoid that and get immutability guarantees as a nice bonus, right? Not so fast, there might be more problems than one could anticipate!
Read more...
Easy parsing of Excel spreadsheet format with Swift's Codable protocols
12 November, 2018
Did you ever need to parse an Excel spreadsheet on iOS, macOS or Linux in Swift? Turns out it’s easier to implement than one would expect, especially with the help of Swift's great Codable protocols. The resulting library is open-source and is available on GitHub.
Read more...
Event loops, building smooth UIs, and handling high server load
16 August, 2018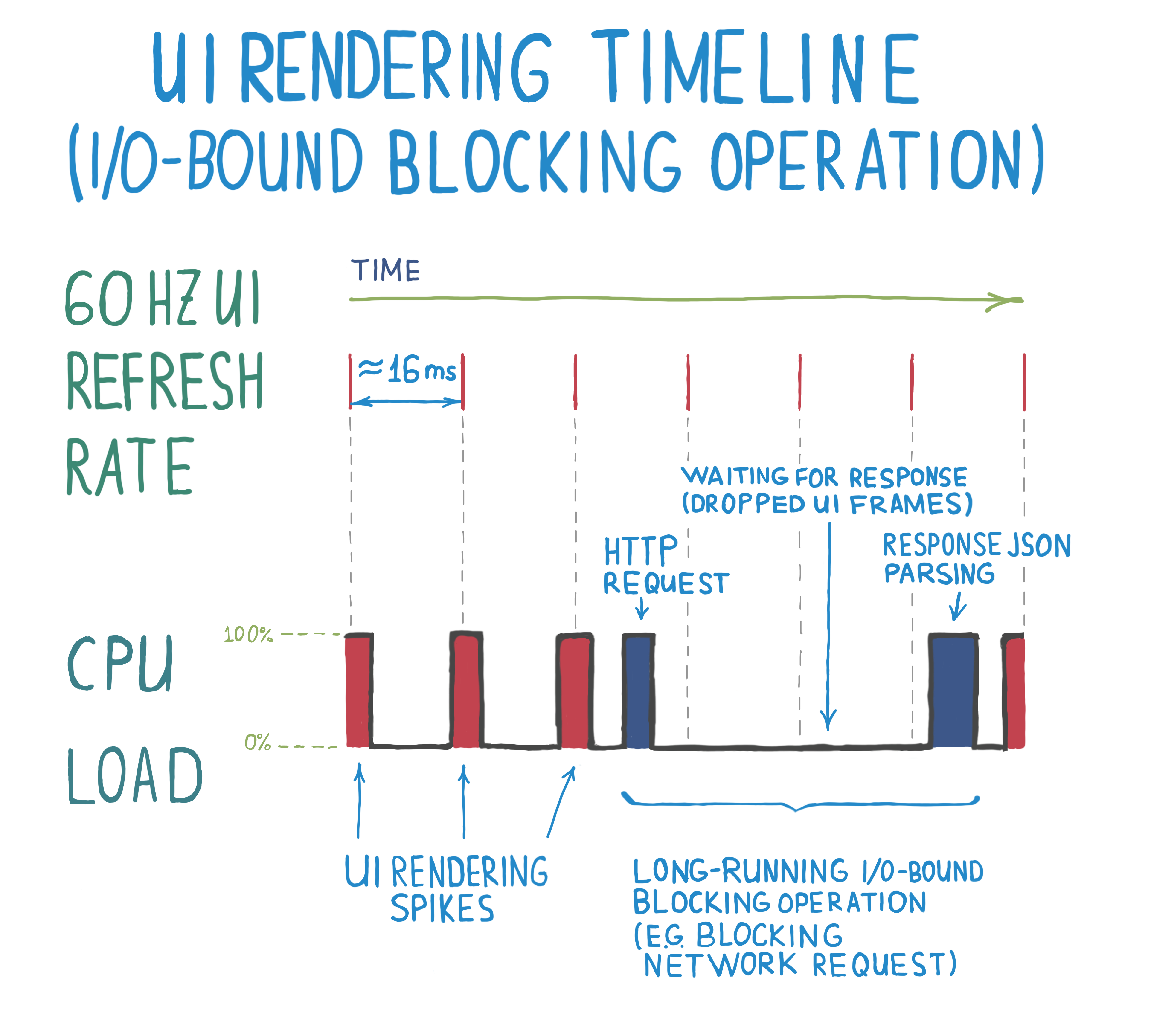
Have you ever used an app that felt unresponsive? Not reacting to input on time, slow animations even for some simple tasks, even when there isn't anything heavy running in the background? Most probably, an app like that is waiting for some blocking long-running computation to finish before consuming more user input or rendering animation frames. Scheduling all workloads correctly and in the right order might seem hard, especially as there are different approaches to choose from.
Read more...
How do closures and callbacks work? It's turtles all the way down
26 June, 2018
In software engineering and computer science, we constantly deal with layers of abstractions, but we don't cross too many of them on daily basis. Here's an abstraction that developers work with a lot: asynchronous computations. These days it's hard to write code that doesn't touch something asynchronous: any kind of I/O, most frequently networking, or maybe long-running tasks that are scheduled on different threads/processes. For something more concrete, consider a database query, which could be local disk I/O or something that sits somewhere on the network. In most cases like this you'd need to use closures or build something more powerful on top of it.
Read more...
Why I use GraphQL and avoid REST APIs
28 May, 2018Recently I had a chance to develop and to run in production a few mobile and web apps built with GraphQL APIs, both for my own projects and my clients. This has been a really good experience, not least thanks to wonderful PostGraphile and Apollo libraries. At this point, it's quite hard for me to come back and enjoy working with REST.
But obviously, this needs a little explanation.